| This article was posted to the LANL preprint server on Feb 16, 2002 and was slashdotted on Feb 17, 2002. A few good points were raised on slashdot and I intend to progressively address them in a Postscript (section 7) as an update to this online version. I will entertain any sensible discussion via this email form initially and direct email thereafter. |
| (1) |
| (2) |
| Topology | δ |
| Tree | 2 h |
| Hypercube | d |
| Torus | d N1/d / 4 |
| (3) |
| (4) |
| (5) |
| Topology | L |
| Tree | Ntree |
| Hypercube | dNcube / 2 |
| Torus | dNtorus |
| (6) |
| (7) |
| (8) |
| (9) |
| (10) |
| (11) |
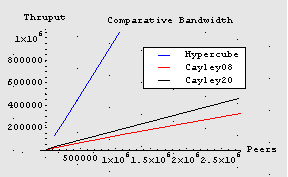
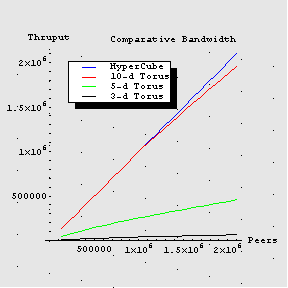
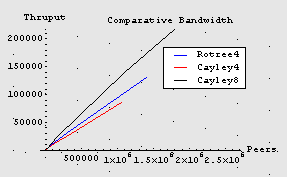
| Network | Connections | Hops to | Peers x 106 | Relative (%) |
| Topology | per Peer | Horizon | in Horizon | Bandwidth |
| 20-Cube | 20 | 10 | 2.1 | 100 |
| 10-Torus | 20 | 11 | 2.1 | 93 |
| 5-Torus | 10 | 23 | 2.1 | 22 |
| 20-Cayley | 20 | 6 | 2.8 | 16 |
| 8-Cayley | 8 | 8 | 1.1 | 13 |
| 4-Tree | 4 | 11 | 1.4 | 12 |
| 3-Torus | 6 | 96 | 2.1 | 10 |
| 4-Cayley | 4 | 13 | 1.1 | 8 |