|
|
Performance Collapse |
The failure of important communcation networks over the last decade has become all too familiar. The entire AT&T phone system was brought to its knees in 1990 by a software bug that escaped the QA process. And a similar problem arose in AT&T frame-relay network on April 14, 1998 that shut down bank ATMs and other business activities. These are examples of sudden, but hard failures, due to "programming" errors of one kind or another.
What is not so obvious is, that a computer network can become degraded
very suddenly even though the average traffic load on the network remains
constant. This sudden congestion manifests itself as a spontaneous collapse
in performance (seen as orders-of-magnitude drop in packets/second delivered) or
a concomitant increase in packet delay. Such effects have been seen on the internet
since 1986 and led to the implementation of the "slow
start" congestion avoidance algorithm for TCP/IP networks
more than 10 years ago. The same algorithm that was intended to avoid high packet
latency is now responsible for latency overhead for HTTP in the world wide
web. Some internet researchers suggest we may be facing a possible "deja vu all over again."
Clearly, it is important to understand the dynamics of this kind of performance collapse,
and oscillation, so
as to choose avoidance strategies that are least sensitive to changes in network
usage. How can we picture the sudden onset of this kind of performance collapse?
For that, we turn to a more familiar but related problem; virtual memory thrashing.
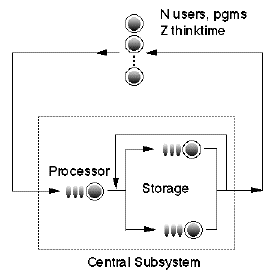
The state of computer system or network is parameterized in conventional queueing
models by
the average length of the fluctuating queues corresponding to contention at
each of the physical resources (e.g., processor, disk, memory, or router) being modeled.
A typical closed-circuit queueing model for a time-share computer system is shown
in the following diagram.
Under certain conditions, however, queues can fluctuate about more than one stable
average length i.e., some queues can have two stable lengths: "short"
and "long" (for some value of short and long). A "long" queue
means that it will take a long time to have any request serviced (on average). More
importantly, the presence of two stable queue lengths implies that the system
may move dynamically between these stable queue lengths in some way. It turns
out that this transition between stable queue lengths can occur very suddenly in
real computer systems (e.g., the onset of "thrashing" in virtual memory
computers usually happens without warning).
Since the queue-lengths are a measure of such important macroscopic performance metrics
as response time, it would be very useful to have both a qualitative
and a quantitative understanding of the dynamics of these large fluctuations
or large transients. In conventional modeling approaches, large transients are difficult
to capture and calculate.
This tutorial will survey a variety of modeling techniques applied to the problems
of stability in computer performance analysis. One such method (the Path-Integral
or Instanton technique) is due to the author and is presented in more detail in PART
III of the book The
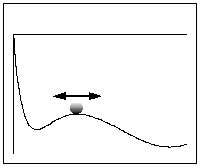
Practical Performance Analyst. The motivation for the approach is depicted schematically
in the following diagram which shows the relationship between the conventional queueing
model throughputs and a "hidden" mean potential function which controls
the stability of the queueing system. The dynamics of the transition to the state
of degraded performance can be easily visualized as the movement of a "ball
bearing" between two "valleys."

With this intuitive representation in place, Dr. Gunther then recognized that the problem of estimating the mean time to transition (MTTT) is analogous to calculating the decay rate of an atom in Quantum Mechanics (he was sure all that physics would come in handy one day!). At this level of detail the "ball bearing" behaves stochastically -- more like speck of dust in water (also known as Brownian motion). The form of the MTTT estimator derived from the path integral is given by the formula:
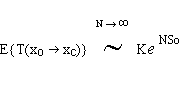
which states that (in the limit of a large number of sources, N) the mean (or
expected) time to reach the top of the "hill" Xc (starting at Xo), is determined
by three constants: N - the system size (e.g., the number of programs or nodes
in a network), So - the cost of climbing the "hill" (related to
the shape of the mean potential in the Figure above), and K - a prefactor
determined formally by the integration measure in the path integral (not discussed
here).
A significant virtue of this formula is that it enables fast numerical computation
(as opposed to doing matrix inversions or long simulations) and could therefore be
used in a predictive way to the shape of the "hill" so as to ensure optimal
performance without the risk of performance collapse. Such a scheme has been
considered for admission control in ATM
networks.
The formal mathematics supporting this intuition can be found in the following papers:
| Gunther, N. J. 1988. A New Interpretation of Computer System Instabilities. Proc. ACM SIGMETRICS Conf., May 24-27, Santa Fe, New Mexico. |
| Gunther, N. J. 1989. Path Integral Methods for Computer Performance Analysis. Information Processing Letters. 32(1): 7-13. |
| Gunther, N. J. 1990. Instanton Techniques for Queueing Models of Large Computer Systems: Getting a Piece of the Action. Invited paper presented at SIAM Conference on Applied Probability in Science and Engineering. March 1990 New Orleans, Louisiana. |
| Gunther, N. J. 1990. Bilinear Model of Blocking Transients in Large Circuit-Switching Networks. In PERFORMANCE ë90, Proceedings of the 14th IFIP WG 7.3 International Symposium on Computer Performance Modelling, Measurement and Evaluation, Edinburgh, Scotland, 12-14, September. Amsterdam: North-Holland. 175-189. |
| Gunther, N. J. 1990. Performance Pathways: The Path Integral View of Computer System Stability. ACM SIGMETRICS Performance Evaluation Review. 17(2): 50. |
| Gunther, N. J., and Shaw, J. G. 1990. Path Integral Evaluation of ALOHA Network Transients. Information Processing Letters, 33(6): 289-295. |