| Page | Spotter | Correction |
| 3 | P. Cañadilla | § 1.2.2, 2nd bullet: "FreeBSD, MacOS X, RedHat Linux" s.b. Red Hat |
| 8 | H. Harper | § 1.3.3, line 7: "It easy" s.b. It is easy |
| 9 | H. Harper | § 1.3.3, line 2 after Fig. 1.2: "likely to confusing" s.b. likely to be confusing |
| 11 | P. Cañadilla | 3rd para after fig 1.4, 2nd line: "input data for Excelregression" s.b. Excel regression |
| 16 | P. Cañadilla | Item Opportunistic Intervention, line 3: "... .Rather then" s.b. than |
| 19 | P. Cañadilla | § 2.2.1. 2nd line: "to provides an appropiate" s.b. provide |
| 20 | P. Cañadilla | Line 5: " a set _ OLAs" insert of |
| " | P. Cañadilla | After fig. 2.2, line 4: "to provide and efficient" s.b. an efficient |
| 21 | P. Cañadilla | Line 4: "capacity homunclulus" s.b. homunculus |
| 22 | P. Cañadilla | Line 2: "development cycle any product" insert of |
| " | P. Cañadilla | Item Measure, line 5: "these data are are fed" Elide second are |
| 23 | P. Cañadilla | Line 3. "Figure 2.3 is meant to convery..." s.b. convey |
| 24 | P. Cañadilla | Line 3 from the bottom: "capacity planning depicited in..." s.b depicted |
| 28 | C. McFarland | Penultimate line of § 3.1: "Once again, these number" s.b. numbers |
| 31 | Author | Table in Example 3.5: Last entry s.b. 24 sigdigs. Must move decimal point 23 places to right. |
| 32 | M. Berger | para 2, line 4: "To help help rectify..." Elide 2nd help |
| " | Author | Algortihm 3.2: The assignment of XYZ needs to be made clearer. See note 1 below. |
| 36 | P. Cañadilla | 5th line: "since it is not a defintion." s.b. definition |
| 39 | P. Cañadilla | § 3.7. Remark 3.4. 2nd item, last term in: ", max(…, ′b × d)]" Elide apostrophe. |
| 49 | T. Wilson | Line above Fig. 4.5: "grapically" s.b. graphically |
| " | T. Wilson | Def. 4.3: "executes in purely sequential of serial fashion" of s.b. or |
| 50 | P. Cañadilla | Last sentence "fraction of time spent in scaler mode" s.b. scalar |
| 51 | P. Stalder | Fig. 4.6 caption s.b. ...serial fraction σ = 0.10 corresponds to... |
| 52 | Author | Eqn. (4.19): The S is shorthand for S(p). Using Sp might be a better choice. |
| 56 | Author | Line 5 from bottom: σ−1 s.b. σ−1 |
| " | T. Wilson | § 4.3.5: [Gustafson 1992] citation missing from bibliography and date s.b. 1988.
See note 3 below. |
| 59 | P. Cañadilla | Example 4.4, 3rd line. "shared writebale data." s.b. writeable |
| 64 | Author | Sect. 4.5.3, Fig. 4.13 and Table 4.1: Names "Exponential," "Amdahl Corp" model is confusing cf. "Amdahl" model.
Use either Exponential or Alohanet. |
| 77 | M. Berger | First line: "we _ more than the three data points..." Insert need |
| 108 | P. Cañadilla | Legend for Figure 6.4: "SQLServer" s.b SQL Server. |
| 112 | P. Chow | § 6.7.3 line 3: Elide because a = 0.0075 while b = 0.0755 |
| 113 | P. Chow | Table 6.8: Using (5.11) for β, (5.12) for α, and (5.15) for N* on p.80,
entries in Table s.b. β = 0.0075 and N* = 11 |
| 116 | R. Hamilton | § 6.9 Line 7 from bottom. "be confiigured..." s.b. configured |
| 123 | P. Cañadilla | Last sentence, "referred to in Sect 11.1." s.b. Sect. 7.1. |
| 135 | M. Berger | Sentence before § 7.4.4: "...became available to the high-priority VMs" s.b. low-priority |
| " | T. Wilson | First complete para: "With the in mind..." the s.b. this |
| 147 | M. Berger | Period missing at end of 2nd para. |
| 147 | P. Cañadilla | Legend for Figure 8.3: "...bimodal curve in Fig. 8.3" s.b. in Fig. 8.1 |
| " | P. Cañadilla | Legend for Figure 8.3: "...two component component curves..." Elide 2nd `component' |
| 149 | P. Cañadilla | § 8.3.2, Line 8: "...measurements than than are generally available..." Elide 2nd than |
| " | P. Cañadilla | § 8.3.2, 5th line: Gunther (2005a) s.b. (Gunther 2005a) |
| 150 | P. Cañadilla | § 8.4.1, 6th line. "VBA is a quite a reasonable..." Elide 1st 'a' |
| 152 | Author | Eqn.(8.1) should only have 4 random variables, not 6 X's.
Two r.v.'s (MinU and MaxU in Fig. 8.5) are used to filter the data. |
| " | Author | The VBA code in Appendix E.2 is correct. |
| 152 | R. Hamilton | 2nd line in § 8.6 "We new present ..." s.b. now |
| 153 | P. Cañadilla | § 8.6.2, 2 lines above: SignificanceF s.b Significance F |
| 154 | R. Schmitt | Last line s.b. "...larger values of Ueff are estimated..." |
| 155 | P. Cañadilla | § 8.7.1, 4th line: "...to a an exponential model" Elide 'a' |
| " | P. Cañadilla | Eqn. (8.2): All `w' subscripts s.b. l.c. Also text 2 lines above (8.2) |
| 156 | P. Cañadilla | Page 156, 1st para, last line: Mismatch b/w U0 = 133.12 in text and y = 135.91e0.0309x in Fig. 8.9 legend |
| 159 | R. Hamilton | Table 8.1: Last digit is missing in each of the ∆CLK numbers. s.b. 36677 and 42340, respectively. |
| 161 | R. Hamilton | Example: 8.3, 1st line: equation should read UC(20) = 246.97% |
| 165 | R. Hamilton | Para 2, line 6. "Mnay of these..." s.b. Many |
| 168 | P. Cañadilla | § 9.4, 3rd line: "and the links to the links to network connections." Elide to the links |
| 169 | P. Cañadilla | Line after eqn. (9.2): "nodes in ( 9.1)." Close up |
| 181 | P. Cañadilla | Para 1, 2nd last line: "20 μs for the arrival time of each packe; the..." ??? |
| 192 | P. Cañadilla | § 10.5.2, 2 lines after eqn. (10.21):" Fig. 10.12 s.b 10.11 |
| 195 | P. Cañadilla | Last para: Drop 2nd ref (private communication, 2005) |
| 217 | Author | D s.b. S in equations A.23 and A.24. |
| 240 | P. Cañadilla | § F.3. Item 1: "quanitatively" s.b. quantitatively |
| 241 | R. Hamilton | Line above § F.3.2: "...reduces to Amdahl's law, as expcted." s.b. expected |
| 251 | Author | Add index entries for Significant digits per Chap. 3 |
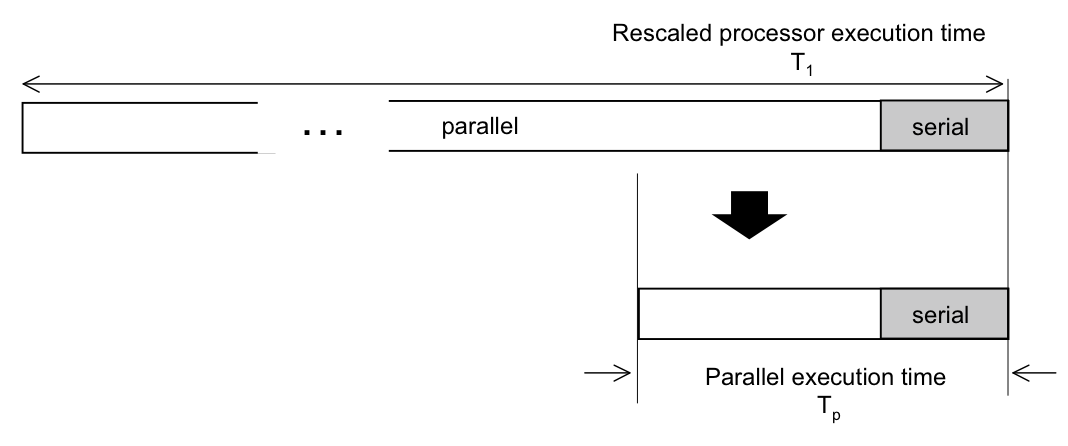 The parallel portion of the work in Fig. 4.5 is first scaled up in proportion to the number
of available processors: (1−σ) → (1−σ) p.
The parallel portion of the work in Fig. 4.5 is first scaled up in proportion to the number
of available processors: (1−σ) → (1−σ) p.