TBD
TBD
A nicely written book with lots of tips mostly centered on HTTPd performance tuning. Heavy on empirical insights, rather weaker on formal analysis.
Presents a combination of formal analysis along with suggestions for data collection and parameterization of formal models. The approach to queueing models is very much in the style of MVA [4] [2] but brought up to date for web technologies.
Similar content to [4] but with an emphasis on database back-end configurations. Narrowly escapes getting into the complexities of modeling such things as thread allocation.
TBD
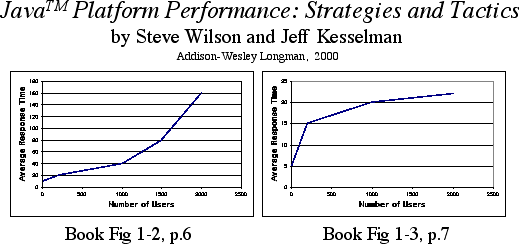
Presents methods for measuring client-side Java performance, mostly through the use of benchmarks. Unfortunately, the authors get off to a bad start in Chap. 1, p. 6 where they discuss the important subject of application scalability.
- They define scalability rather narrowly as ''the study of how systems perform under heavy loads.'' I would prefer they had said, under increasing user load. After all, contention may set in with just a few active users.
- Referring next to Fig. 1-2 (above) which depicts a generic hockey-stick shaped response-time characteristic, the authors claim this as evidence of an application ''that isn't scaling well.'' This conclusion is apparently keyed off the incorrect statement that the response time is increasing ''exponentially'' with increasing user load. No other evidence is provided to support this claim.
- Not only is the response time not rising exponentially, the application may be scaling as well as it can on that platform. Queueing theory also tells us that the response time rises linearly up the hockey-stick handle; not exponentially. Moreover, such behavior does not, by itself, imply poor scalability.
- The response time curve may rise super-linearly in the presence of thrashing effects, but this special case is not discussed by the authors.
- To make matters worse, the authors next refer to Figure 1-3 on p.7 (shown here on the right) which depicts a response time curve that tends to flatten out as user load increases. (It actually looks more like a throughput characteristic). This is presented as an example of an application that ''scales in a more desirable manner'' because the response time degradation is more gradual.
- Assuming the authors have not mislabeled the plot (and the text indicates that they have not), they have failed to comprehend that the flattening effect is most likely caused by throttling due to a limit on the number of threads that the client can execute or the inability of the server to keep up with requests, or something similar. Whatever the precise cause, this sublinear over-saturation effect needs to be investigated as an undesirable measurement effect rather than a desirable scaling feature.
Qualitative treatment with an emphasis on the server-side of web technology. In many ways, a nice compliment to Killelea's book [3]. Becoming a bit dated now.