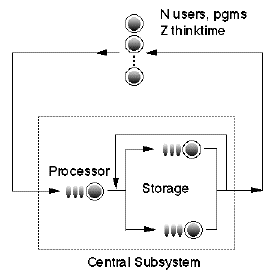
The real risk of everything is collapse. Nobody utters this loudly enough, but the real issue for the world is a collapse of the network or some local collapses. We are the people with pipes. We are supposed to invest heavily in pipes in order to bring the capacity which is necessary to sustain the explosion of consumption and usage and data traffic in our networks. At the same time, the people that create this traffic are not really incentivized to manage properly, globally, the traffic. There is an unbalance in the overall system, which in our view is a major problem.As outlined below, the mathematical tools for analyzing such important and difficult network capacity problems (some of which I helped to develop [2,4,6]), have been around for about 25 years. A more detailed treatment is presented in Part III of my book The Practical Performance Analyst.

| (1) |